Setting a Target for Mean Absolute Prediction Error
/Until today I've never known why an MAPE of 30 was a sensible target, other than that this seemed to be roughly the figure that the TAB Sportsbet bookmaker achieved each year.
Read MoreAs so many traders discovered to their individual and often, regrettably, our collective cost over the past few years, betting against longshots, deliberately or implicitly, can be a very lucrative gig until an event you thought was a once-in-a-virtually-never affair crops up a couple of times in a week. And then a few more times again after that.
To put a footballing context on the topic, let's imagine that a friend puts the following proposition bet to you: if none of the first 100 home-and-away games next season includes one with a handicap-adjusted margin (HAM) for the home team of -150 or less he'll pay you $100; if there is one or more games with a HAM of -150 or less, however, you pay him $10,000.
For clarity, by "handicap-adjusted margin" I mean the number that you get if you subtract the away team's score from the home team's score and then add the home team's handicap. So, for example, if the home team was a 10.5 point favourite but lost 100-75, then the handicap adjusted margin would be 75-100-10.5, or -35.5 points.
At first blush, does the bet seem fair?
We might start by relying on the availability heuristic and ask ourselves how often we can recall a game that might have produced a HAM of -150 or less. To make that a tad more tangible, how often can you recall a team losing by more than 150 points when it was roughly an equal favourite or by, say, 175 points when it was a 25-point underdog?
Almost never, I'd venture. So, offering 100/1 odds about this outcome occurring once or more in 100 games probably seems attractive.
Maybe you're a little more empirical than that and you'd like to know something about the history of HAMs. Well, since 2006, which is a period covering just under 1,000 games and that spans the entire extent - the whole hog, if you will - of my HAM data, there's never been a HAM under -150.
One game produced a -143.5 HAM; the next lowest after that was -113.5. Clearly then, the HAM of -143.5 was an outlier, and we'd need to see another couple of scoring shots on top of that effort in order to crack the -150 mark. That seems unlikely.
In short, we've never witnessed a HAM of -150 or less in about 1,000 games. On that basis, the bet's still looking good.
Before we commit ourselves to the bet, let's consider what else we know about HAMs.
Previously, I've claimed that HAMs seemed to follow a normal distribution and, in fact, the HAM data comfortably passes the Kolmogorov-Smirnov test of Normality (one of the few statistical tests I can think of that shares at least part of its name with the founder of a distillery).
Now technically the HAM data's passing this test means only that we can't reject the null hypothesis that it follows a Normal distribution, not that we can positively assert that it does. But given the ubiquity of the Normal distribution, that's enough prima facie evidence to proceed down this path of enquiry.
To do that we need to calculate a couple of summary statistics for the HAM data. Firstly, we need to calculate the mean, which is +2.32 points, and then we need to calculate the standard deviation, which is 36.97 points. A HAM of -150 therefore represents an event approximately 4.12 standard deviations from the mean.
If HAMs are Normal, that's certainly a once-in-a-very-long-time event. Specifically, it's an event we should expect to see only about every 52,788 games, which, to put it in some context, is almost exactly 300 times the length of the 2010 home-and-away season.
With a numerical estimate of the likelihood of seeing one such game we can proceed to calculate the likelihood of seeing one or more such game within the span of 100 games. The calculation is 1-(1-1/52,788)^100 or 0.19%, which is about 525/1 odds. At those odds you should expect to pay out that $10,000 about 1 time in 526, and collect that $100 on the 525 other occasions, which gives you an expected profit of $80.81 every time you take the bet.
That still looks like a good deal.
This latest estimate carries all the trappings of statistically soundness, but it does hinge on the faith we're putting in that 1 in 52,788 estimate, which, in turn hinges on our faith that HAMs are Normal. In the current instance this faith needs to hold not just in the range of HAMs that we see for most games - somewhere in the -30 to +30 range - but way out in the arctic regions of the distribution rarely seen by man, the part of the distribution that is technically called the 'tails'.
There are a variety of phenomena that can be perfectly adequately modelled by a Normal distribution for most of their range - financial returns are a good example - but that exhibit what are called 'fat tails', which means that extreme values occur more often than we would expect if the phenomenon faithfully followed a Normal distribution across its entire range of potential values. For most purposes 'fat tails' are statistically vestigial in their effect - they're an irrelevance. But when you're worried about extreme events, as we are in our proposition bet, they matter a great deal.
A class of distributions that don't get a lot of press - probably because the branding committee that named them clearly had no idea - but that are ideal for modelling data that might have fat tails are the Stable Distributions. They include the Normal Distribution as a special case - Normal by name, but abnormal within its family.
If we fit (using Maximum Likelihood Estimation if you're curious) a Stable Distribution to the HAM data we find that the best fit corresponds to a distribution that's almost Normal, but isn't quite. The apparently small difference in the distributional assumption - so small that I abandoned any hope of illustrating the difference with a chart - makes a huge difference in our estimate of the probability of losing the bet. Using the best fitted Stable Distribution, we'd now expect to see a HAM of -150 or lower about 1 game in every 1,578 which makes the likelihood of paying out that $10,000 about 7%.
Suddenly, our seemingly attractive wager has a -$607 expectation.
Since we almost saw - if that makes any sense - a HAM of -150 in our sample of under 1,000 games, there's some intuitive appeal in an estimate that's only a bit smaller than 1 in 1,000 and not a lot smaller, which we obtained when we used the Normal approximation.
Is there any practically robust way to decide whether HAMs truly follow a Normal distribution or a Stable Distribution? Given the sample that we have, not in the part of the distribution that matters to us in this instance: the tails. We'd need a sample many times larger than the one we have in order to estimate the true probability to an acceptably high level of certainty, and by then would we still trust what we'd learned from games that were decades, possibly centuries old?
The issue here, and what inspired me to write this blog, is the oft-neglected truism - an observation that I've read and heard Nassim Taleb of "Black Swan" fame make on a number of occasions - that rare events are, well, rare, and so estimating their likelihood is inherently difficult and, if you've a significant interest in the outcome, financially or otherwise dangerous.
For many very rare events we simply don't have sufficiently large or lengthy datasets on which to base robust probability estimates for those events. Even where we do have large datasets we still need to justify a belief that the past can serve as a reasonable indicator of the future.
What if, for example, the Gold Coast team prove to be particularly awful next year and get thumped regularly and mercilessly by teams of the Cats' and the Pies' pedigrees? How good would you feel than about betting against a -150 HAM?
So when some group or other tells you that a potential catastrophe is a 1-in-100,000 year event, ask them what empirical basis they have for claiming this. And don't bet too much on the fact that they're right.
So far we've learned that handicap-adjusted margins appear to be normally distributed with a mean of zero and a standard deviation of 37.7 points. That means that the unadjusted margin - from the favourite's viewpoint - will be normally distributed with a mean equal to minus the handicap and a standard deviation of 37.7 points. So, if we want to simulate the result of a single game we can generate a random Normal deviate (surely a statistical contradiction in terms) with this mean and standard deviation.
Alternatively, we can, if we want, work from the head-to-head prices if we're willing to assume that the overround attached to each team's price is the same. If we assume that, then the home team's probability of victory is the head-to-head price of the underdog divided by the sum of the favourite's head-to-head price and the underdog's head-to-head price.
So, for example, if the market was Carlton $3.00 / Geelong $1.36, then Carlton's probability of victory is 1.36 / (3.00 + 1.36) or about 31%. More generally let's call the probability we're considering P%.
Working backwards then we can ask: what value of x for a Normal distribution with mean 0 and standard deviation 37.7 puts P% of the distribution on the left? This value will be the appropriate handicap for this game.
Again an example might help, so let's return to the Carlton v Geelong game from earlier and ask what value of x for a Normal distribution with mean 0 and standard deviation 37.7 puts 31% of the distribution on the left? The answer is -18.5. This is the negative of the handicap that Carlton should receive, so Carlton should receive 18.5 points start. Put another way, the head-to-head prices imply that Geelong is expected to win by about 18.5 points.
With this result alone we can draw some fairly startling conclusions.
In a game with prices as per the Carlton v Geelong example above, we know that 69% of the time this match should result in a Geelong victory. But, given our empirically-based assumption about the inherent variability of a football contest, we also know that Carlton, as well as winning 31% of the time, will win by 6 goals or more about 1 time in 14, and will win by 10 goals or more a litle less than 1 time in 50. All of which is ordained to be exactly what we should expect when the underlying stochastic framework is that Geelong's victory margin should follow a Normal distribution with a mean of 18.8 points and a standard deviation of 37.7 points.
So, given only the head-to-head prices for each team, we could readily simulate the outcome of the same game as many times as we like and marvel at the frequency with which apparently extreme results occur. All this is largely because 37.7 points is a sizeable standard deviation.
Well if simulating one game is fun, imagine the joy there is to be had in simulating a whole season. And, following this logic, if simulating a season brings such bounteous enjoyment, simulating say 10,000 seasons must surely produce something close to ecstasy.
I'll let you be the judge of that.
Anyway, using the Wednesday noon (or nearest available) head-to-head TAB Sportsbet prices for each of Rounds 1 to 20, I've calculated the relevant team probabilities for each game using the method described above and then, in turn, used these probabilities to simulate the outcome of each game after first converting these probabilities into expected margins of victory.
(I could, of course, have just used the line betting handicaps but these are posted for some games on days other than Wednesday and I thought it'd be neater to use data that was all from the one day of the week. I'd also need to make an adjustment for those games where the start was 6.5 points as these are handled differently by TAB Sportsbet. In practice it probably wouldn't have made much difference.)
Next, armed with a simulation of the outcome of every game for the season, I've formed the competition ladder that these simulated results would have produced. Since my simulations are of the margins of victory and not of the actual game scores, I've needed to use points differential - that is, total points scored in all games less total points conceded - to separate teams with the same number of wins. As I've shown previously, this is almost always a distinction without a difference.
Lastly, I've repeated all this 10,000 times to generate a distribution of the ladder positions that might have eventuated for each team across an imaginary 10,000 seasons, each played under the same set of game probabilities, a summary of which I've depicted below. As you're reviewing these results keep in mind that every ladder has been produced using the same implicit probabilities derived from actual TAB Sportsbet prices for each game and so, in a sense, every ladder is completely consistent with what TAB Sportsbet 'expected'.
The variability you're seeing in teams' final ladder positions is not due to my assuming, say, that Melbourne were a strong team in one season's simulation, an average team in another simulation, and a very weak team in another. Instead, it's because even weak teams occasionally get repeatedly lucky and finish much higher up the ladder than they might reasonably expect to. You know, the glorious uncertainty of sport and all that.
Consider the row for Geelong. It tells us that, based on the average ladder position across the 10,000 simulations, Geelong ranks 1st, based on its average ladder position of 1.5. The barchart in the 3rd column shows the aggregated results for all 10,000 simulations, the leftmost bar showing how often Geelong finished 1st, the next bar how often they finished 2nd, and so on.
The column headed 1st tells us in what proportion of the simulations the relevant team finished 1st, which, for Geelong, was 68%. In the next three columns we find how often the team finished in the Top 4, the Top 8, or Last. Finally we have the team's current ladder position and then, in the column headed Diff, a comparison of the each teams' current ladder position with its ranking based on the average ladder position from the 10,000 simulations. This column provides a crude measure of how well or how poorly teams have fared relative to TAB Sportsbet's expectations, as reflected in their head-to-head prices.
Here are a few things that I find interesting about these results:
(In another blog I've used the same simulation methodology to simulate the last two rounds of the season and project where each team is likely to finish.)
Okay, this is probably going to be a long blog so you might want to make yourself comfortable.
For some time now I've been wondering about the statistical properties of the Handicap-Adjusted Margin (HAM). Does it, for example, follow a normal distribution with zero mean?
Well firstly we need to deal with the definition of the term HAM, for which there is - at least - two logical definitions.
The first definition, which is the one I usually use, is calculated from the Home Team perspective and is Home Team Score - Away Team Score + Home Team's Handicap (where the Handicap is negative if the Home Team is giving start and positive otherwise). Let's call this Home HAM.
As an example, if the Home Team wins 112 to 80 and was giving 20.5 points start, then Home HAM is 112-80-20.5 = +11.5 points, meaning that the Home Team won by 11.5 points on handicap.
The other approach defines HAM in terms of the Favourite Team and is Favourite Team Score - Underdog Team Score + Favourite Team's Handicap (where the Handicap is always negative as, by definition the Favourite Team is giving start). Let's call this Favourite HAM.
So, if the Favourite Team wins 82 to 75 and was giving 15.5 points start, then Favourite HAM is 82-75-15.5 = -7.5 points, meaning that the Favourite Team lost by 7.5 points on handicap.
Home HAM will be the same as Favourite HAM if the Home Team is Favourite. Otherwise Home HAM and Favourite HAM will have opposite signs.
There is one other definitional detail we need to deal with and that is which handicap to use. Each week a number of betting shops publish line markets and they often differ in the starts and the prices offered for each team. For this blog I'm going to use TAB Sportsbet's handicap markets.
TAB Sportsbet Handicap markets work by offering even money odds (less the vigorish) on both teams, with one team receiving start and the other offering that same start. The only exception to this is when the teams are fairly evenly matched in which case the start is fixed at 6.5 points and the prices varied away from even money as required. So, for example, we might see Essendon +6.5 points against Carlton but priced at $1.70 reflecting the fact that 6.5 points makes Essendon in the bookie's opinion more likely to win on handicap than to lose. Games such as this are problematic for the current analysis because the 'true' handicap is not 6.5 points but is instead something less than 6.5 points. Including these games would bias the analysis - and adjusting the start is too complex - so we'll exclude them.
So, the question now becomes is HAM Home, defined as above and using the TAB Sportsbet handicap and excluding games with 6.5 points start or fewer, normally distributed with zero mean? Similarly, is HAM Favourite so distributed?
We should expect HAM Home and HAM Favourite to have zero means because, if they don't it suggests that the Sportsbet bookie has a bias towards or against Home teams of Favourites. And, as we know, in gambling, bias is often financially exploitable.
There's no particular reason to believe that HAM Home and HAM Favourite should follow a normal distribution, however, apart from the startling ubiquity of that distribution across a range of phenomena.
Consider first the issue of zero means.
The following table provides information about Home HAMs for seasons 2006 to 2008 combined, for season 2009, and for seasons 2006 to 2009. I've isolated this season because, as we'll see, it's been a slightly unusual season for handicap betting.
Each row of this table aggregates the results for different ranges of Home Team handicaps. The first row looks at those games where the Home Team was offering start of 30.5 points or more. In these games, of which there were 53 across seasons 2006 to 2008, the average Home HAM was 1.1 and the standard deviation of the Home HAMs was 39.7. In season 2009 there have been 17 such games for which the average Home HAM has been 14.7 and the standard deviation of the Home HAMs has been 29.1.
The asterisk next to the 14.7 average denotes that this average is statistically significantly different from zero at the 10% level (using a two-tailed test). Looking at other rows you'll see there are a handful more asterisks, most notably two against the 12.5 to 17.5 points row for season 2009 denoting that the average Home HAM of 32.0 is significant at the 5% level (though it is based on only 8 games).
At the foot of the table you can see that the overall average Home HAM across seasons 2006 to 2008 was, as we expected approximately zero. Casting an eye down the column of standard deviations for these same seasons suggests that these are broadly independent of the Home Team handicap, though there is some weak evidence that larger absolute starts are associated with slightly larger standard deviations.
For season 2009, the story's a little different. The overall average is +8.4 points which, the asterisks tell us, is statistically significantly different from zero at the 5% level. The standard deviations are much smaller and, if anything, larger absolute margins seem to be associated with smaller standard deviations.
Combining all the seasons, the aberrations of 2009 are mostly washed out and we find an average Home HAM of just +1.6 points.
Next, consider Favourite HAMs, the data for which appears below:
The first thing to note about this table is the fact that none of the Favourite HAMs are significantly different from zero.
Overall, across seasons 2006 to 2008 the average Favourite HAM is just 0.1 point; in 2009 it's just -3.7 points.
In general there appears to be no systematic relationship between the start given by favourites and the standard deviation of the resulting Favourite HAMs.
Summarising:
Okay then, are Home HAMs and Favourite HAMs normally distributed?
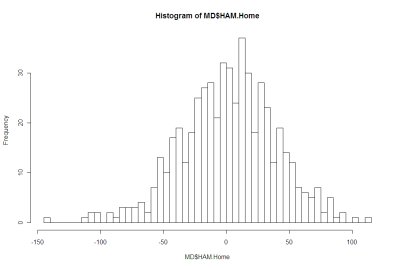
Here's a histogram of Home HAMs:
And here's a histogram of Favourite HAMs:
There's nothing in either of those that argues strongly for the negative.
More formally, Shapiro-Wilks tests fail to reject the null hypothesis that both distributions are Normal.
Using this fact, I've drawn up a couple of tables that compare the observed frequency of various results with what we'd expect if the generating distributions were Normal.
Here's the one for Home HAMs:
There is a slight over-prediction of negative Home HAMs and a corresponding under-prediction of positive Home HAMs but, overall, the fit is good and the appropriate Chi-Squared test of Goodness of Fit is passed.
And, lastly, here's the one for Home Favourites:
In this case the fit is even better.
We conclude then that it seems reasonable to treat Home HAMs as being normally distributed with zero mean and a standard deviation of 37.7 points and to treat Favourite HAMs as being normally distributed with zero mean and, curiously, the same standard deviation. I should point out for any lurking pedant that I realise neither Home HAMs nor Favourite HAMs can strictly follow a normal distribution since Home HAMs and Favourite HAMs take on only discrete values. The issue really is: practically, how good is the approximation?
This conclusion of normality has important implications for detecting possible imbalances between the line and head-to-head markets for the same game. But, for now, enough.
We statisticians spend a lot of our lives dealing with the bell-shaped statistical distribution known as the Normal or Gaussian distribution. It describes a variety of phenomena in areas as diverse as physics, biology, psychology and economics and is quite frankly the 'go-to' distribution for many statistical purposes.
So, it's nice to finally find a footy phenomenon that looks Normally distributed.
The statistic is the percentage of points scored by each team is a game and the distribution of this statistic is shown for the periods 1897 to 2008 and 1980 to 2008 in the diagram below.
Both distributions follow a Normal distribution quite well except in two regards:
Knowledge of this fact is unlikely to make you wealthy but it does tell us that we should expect approximately:
The most recent occurrence of a team scoring about 90% of the points in a game was back in Round 15 of 1989 when Essendon 25.10 (160) defeated West Coast 1.12 (18).
We're overdue for another game with this sort of lopsided result.
MAFL is a website for ...
![]() Click on the envelope
Click on the envelope
Copyright © 2006-2025, Tony Corke. All rights reserved.